Habt ihr euch schon mal gefragt, wie ein Computer ein Bild zwischen Katze und Hund unterscheiden kann? Häufig steckt dahinter die Technologie Deep Learning. Dabei handelt es sich nicht um eine neue Entwicklung, denn die Technologie existiert nämlich bereits seit den 60er Jahren. Jedoch gewinnt sie in heutiger Zeit immer mehr an Relevanz. Der Grund dafür ist, dass die Rechenleistung von Computern immer weiter steigt und auch vorhandene Datenmengen immer größer werden.
In diesem Blogbeitrag wollen wir euch nun eine Einführung in das Thema Deep Learning geben. Wir zeigen euch, wie es funktioniert und welche weiteren Anwendungsfälle es neben der Unterscheidung zwischen Hund und Katze noch gibt.
Was ist Deep Learning?
Bei Deep Learning handelt es sich um einen Teilbereich des Machine Learning. Es zählt somit zu einer Technologie der künstlichen Intelligenz. Dabei werden tiefe Künstliche Neuronale Netze (KNN) – angelehnt an menschliche Nervenzellen im Gehirn – verwendet. Diese werden anhand von Beispieldaten trainiert, um ein Modell für die Daten abzuleiten. Einfacher ausgedrückt kann man auch sagen, dass das Modell anhand von Beispielen Fähigkeiten erlernen kann. Durch das Modell ist es letztendlich möglich Entscheidungen oder Prognosen anhand neuer Daten zu erstellen.

Soll das Deep Learning Modell eine Fähigkeit in all ihren Facetten lernen, ist es notwendig, dass möglichst viele Datensätze oder Beispiele vorhanden sind. Dadurch bietet sich die Verwendung des Modells in Kombination mit Big Data an, da hier enorm große Datenmengen bereitstehen, anhand derer das Modell lernen kann.
Nur damit ihr ein Gefühl für die Größe solcher Datensätze bekommt: Der TensorFlow Datensatz zur Unterscheidung zwischen Katze und Hund ist mit 23.000 Bildern noch ein relativ kleiner Datensatz, verglichen mit beispielsweise dem ImageNet Datensatz mit rund 14 Millionen Bildern.
Deep Learning vs. klassisches Machine Learning
Wie bereits im vorherigen Abschnitt erwähnt, ist Deep Learning eine Teildisziplin des Machine Learning, bei der sich bestimmte Unterschiede definieren lassen.
Unter den klassischen Machine Learning Methoden verstehen wir Methoden des Machine Learning, die keine Künstlichen Neuronalen Netze verwenden. Das sind beispielsweise Methoden, wie die Regressionsanalyse oder Entscheidungsbäume.
Der Hauptunterschied besteht jedoch in der Art der Daten, die die Methoden verarbeiten können. So sind für klassisches Machine Learning strukturierte Daten notwendig. Sollten diese nur in unstrukturierter Form vorliegen, müssen sie erst von einem Menschen in strukturierte Daten transformiert werden.
Ein KNN kann jedoch lernen aus jeder Art von Daten die notwendigen Informationen zu extrahieren. Wohingegen Deep Learning tendenziell mit allen Daten(arten) arbeiten kann. Wenn ihr mehr über strukturierte und unstrukturierte Daten erfahren möchtet, schaut euch unseren Blogbeitrag „Automatisierte Datenverarbeitung – Was sind strukturierte und unstrukturierte Daten?“ an.
Die Hauptunterschiede sind also folgende:

Deep Learning und Neuronale Netze
Künstliche Neuronale Netze bilden die Grundlage für alle Deep Learning Modelle. Doch was sind KNN überhaupt und wie sind sie aufgebaut?

Künstliche Neuronale Netze bestehen grundlegend aus verschiedenen Schichten. Jede einzelne dieser Schichten besteht aus mehreren gleichartigen Neuronen, die eine Analogie zu den Nervenzellen im menschlichen Gehirn darstellen. Hier unterscheidet man zwischen Eingabeschicht, Ausgabeschicht und verborgener Schicht. Die Eingabeschicht erhält die Eingabe für das Modell, beispielsweise ein Bild mit einer Katze. Die verborgenen Schichten errechnen dann anhand der eingegebenen Daten Zwischenwerte, woraus die Ausgabeschicht das Ergebnis für die eingegebenen Daten bestimmt.
Die Verbindungen zwischen den Schichten im Künstlichen Neuronalen Netz definieren dessen Architektur. Je mehr Verbindungen zwischen Schichten existieren, desto komplexer wird die Architektur und somit auch das Modell.
Bei der Verwendung von vielen verborgenen Schichten im Modell spricht man von tiefen Künstlichen Neuronalen Netzen. Daraus leitet sich die englische Bezeichnung „Deep Learning“ ab. Mehr dazu erfahrt ihr in unserem Blogartikel zum Thema Neuronale Netze.
So funktioniert Deep Learning
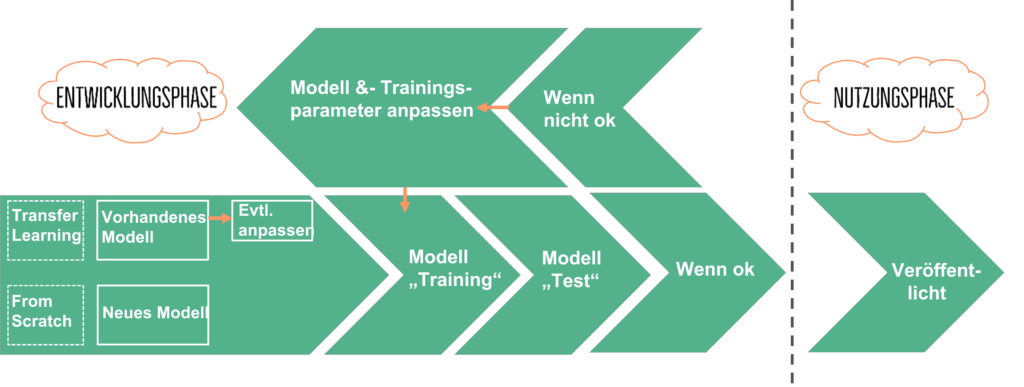
Es gibt im Allgemeinen zwei Best Practice Ansätze, wie du ein Deep Learning Modell trainieren kannst:
Nachdem ein Deep Learning Modell trainiert wurde, ist es bereit veröffentlicht zu werden. Dafür werden diese Modelle häufig auf Webservern ausgeführt und hinter einer API versteckt. An diese können Nutzer*innen Anfragen mit den notwendigen Eingabedaten für das Modell senden und erhalten als Antwort das vom Modell bestimmte Ergebnis.
Anwendungsbereiche
Deep Learning besitzt viele unterschiedliche Anwendungsbereiche, zu denen immer wieder neue hinzukommen.
Ein sehr bekanntes Beispiel sind diverse Sprachassistenten wie Siri oder der Google Assistant. Sie sind durch Deep Learning in der Lage, Sprachbefehle zu verstehen und daraus kontextbasiert Aktionen auszuführen.
Ansonsten gibt es noch weitere Anwendungsbereiche, wie zum Beispiel:
Ausblick
In diesem Blogartikel konnten wir euch lediglich einen kleinen Überblick über das komplexe Thema Deep Learning geben. Es gibt noch viele weitere Aspekte, die wir hier noch nicht betrachtet haben. Zum Abschluss möchten wir noch paar Tipps mit euch teilen:
Deep Learning Modelle werden mit besserer Hardware immer leistungsfähiger werden. Deswegen können wir davon ausgehen, dass in den nächsten Jahren immer mehr Anwendungsfälle gefunden werden und es immer weiter in unser Leben tritt. Wir können daher nur mit Spannung beobachten, welche neuen Anwendungsweisen auf uns zu kommen und wie sie unser Leben verändern und beeinflussen werden.
Hallo Herr Dontsov, wären Sie so freundlich und würden das Veröffentlichkeitsdatum noch benennen? Vielen Dank und viele Grüße Jana
Hallo Jana,
das Veröffentlichungsdatum ist der 24.08.2021.
Viele Grüße
Artem